Blend混合SIMD小试
不太对,再更新下
#include <cstring>
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <string>
#include <stdint.h>
#include <immintrin.h>
#include <smmintrin.h>
#include "thirdparty/libass/include/ass.h"
#include <chrono>
#if defined(_WIN32) || defined(_WIN64)
#define POPEN _popen
#define PCLOSE _pclose
const char *kOpenOption = "wb";
#else
#define POPEN popen
#define PCLOSE pclose
const char *kOpenOption = "w";
#endif
extern "C" {
int ass_process_events_line(ASS_Track *track, char *str);
}
ASS_Library *ass_library;
ASS_Renderer *ass_renderer;
typedef struct image_s {
int width, height, stride;
unsigned char *buffer; // RGB24
} image_t;
void msg_callback(int level, const char *fmt, va_list va, void *data) {
if (level > 6)
return;
printf("libass: ");
vprintf(fmt, va);
printf("\n");
}
#define TO_R(c) ((c) >> 24)
#define TO_G(c) (((c) >> 16) & 0xFF)
#define TO_B(c) (((c) >> 8) & 0xFF)
#define TO_A(c) ((c)&0xFF)
inline void blend_single(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned char r = TO_R(img->color);
unsigned char g = TO_G(img->color);
unsigned char b = TO_B(img->color);
unsigned char *src;
unsigned char *dst;
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0; x < img->w; ++x) {
uint32_t k = ((uint32_t)src[x]) * opacity;
// possible endianness problems...
// would anyone actually use big endian machine??
dst[x * 4] = (k * r + (255 * 255 - k) * dst[x * 4]) / (255 * 255);
dst[x * 4 + 1] = (k * g + (255 * 255 - k) * dst[x * 4 + 1]) / (255 * 255);
dst[x * 4 + 2] = (k * b + (255 * 255 - k) * dst[x * 4 + 2]) / (255 * 255);
dst[x * 4 + 3] = (k * 255 + (255 * 255 - k) * dst[x * 4 + 3]) / (255 * 255);
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single(frame, img);
++cnt;
img = img->next;
}
// printf("%d images blended\n", cnt);
}
inline int div_255_fast(int x) {
return (((x) + (((x) + 257) >> 8)) >> 8);
}
//#define div_255_fast(A) ((A) / 255)
inline void blend_single_normal_fast_div_single(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned char r = TO_R(img->color);
unsigned char g = TO_G(img->color);
unsigned char b = TO_B(img->color);
unsigned char *src;
unsigned char *dst;
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0; x < img->w; ++x) {
unsigned k = div_255_fast(((unsigned)src[x]) * opacity);
// possible endianness problems
dst[x * 4] = div_255_fast(k * r + (255 - k) * dst[x * 4]);
dst[x * 4 + 1] = div_255_fast(k * g + (255 - k) * dst[x * 4 + 1]);
dst[x * 4 + 2] = div_255_fast(k * b + (255 - k) * dst[x * 4 + 2]);
dst[x * 4 + 3] = div_255_fast(k * 255 + (255 - k) * dst[x * 4 + 3]);
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_normal_fast_div(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_normal_fast_div_single(frame, img);
++cnt;
img = img->next;
}
// printf("%d images blended\n", cnt);
}
#if 1
static inline __m128i _mm_fast_div_255_epu16(__m128i x) {
return _mm_srli_epi16(
_mm_adds_epu16(x, _mm_srli_epi16(_mm_adds_epu16(x, _mm_set1_epi16(0x0101)), 8)),
8);
}
void blend_single_u16_simd_method7(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
uint32_t rgba = _byteswap_ulong(img->color) | 0xFF;
unsigned char *src;
unsigned char *dst, *now_dst;
const int img_w_tmp = img->w;
__m128i zeros = _mm_setzero_si128();
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0, now_dst = dst; x <= img_w_tmp - 2;) {
__m128i rgb_v = _mm_set1_epi32(rgba);
rgb_v = _mm_unpacklo_epi8(rgb_v, zeros);
__m128i low_k = _mm_set1_epi16(src[x]);
__m128i high_k1 = _mm_set1_epi16(src[x + 1]);
__m128i k_v = _mm_unpackhi_epi64(low_k, high_k1);
high_k1 = _mm_set1_epi16(opacity);
k_v = _mm_mullo_epi16(k_v, high_k1);
k_v = _mm_fast_div_255_epu16(k_v);
high_k1 = _mm_mullo_epi16(k_v, rgb_v);
low_k = _mm_set1_epi16(255);
rgb_v = _mm_sub_epi16(low_k, k_v);
low_k = _mm_loadl_epi64((__m128i *)(now_dst));
low_k = _mm_unpacklo_epi8(low_k, zeros);
low_k = _mm_mullo_epi16(rgb_v, low_k);
low_k = _mm_add_epi16(high_k1, low_k);
low_k = _mm_fast_div_255_epu16(low_k);
low_k = _mm_packus_epi16(low_k, zeros);
_mm_storeu_si64(now_dst, low_k);
x += 2;
now_dst += 8;
}
if (x < img_w_tmp) {
__m128i rgb_v = _mm_set1_epi32(rgba);
rgb_v = _mm_unpacklo_epi8(rgb_v, zeros);
__m128i low_k = _mm_set1_epi16(src[x]);
__m128i k_v = _mm_set1_epi16(opacity);
k_v = _mm_mullo_epi16(k_v, low_k);
k_v = _mm_fast_div_255_epu16(k_v);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
low_k = _mm_set1_epi16(255);
k_v = _mm_sub_epi16(low_k, k_v);
rgb_v = _mm_loadu_si32((__m128i *)(now_dst));
rgb_v = _mm_unpacklo_epi8(rgb_v, zeros);
rgb_v = _mm_mullo_epi16(k_v, rgb_v);
rgb_v = _mm_add_epi16(mul_1, rgb_v);
rgb_v = _mm_fast_div_255_epu16(rgb_v);
rgb_v = _mm_packs_epi16(rgb_v, zeros);
_mm_storeu_si32(now_dst, rgb_v);
}
src += img->stride;
dst += frame->stride;
}
}
void blend_u16_simd7(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd_method7(frame, img);
++cnt;
img = img->next;
}
}
void blend_single_u16_simd_method6(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
uint32_t rgba = _byteswap_ulong(img->color) | 0xFF;
unsigned char *src;
unsigned char *dst, *now_dst;
const int img_w_tmp = img->w;
__m128i zeros = _mm_setzero_si128();
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0, now_dst = dst; x <= img_w_tmp - 2;) {
__m128i rgb_v = _mm_set1_epi32(rgba);
rgb_v = _mm_unpacklo_epi8(rgb_v, zeros);
uint16_t k = ((unsigned int)src[x]) * opacity;
uint16_t k1 = ((unsigned int)src[x + 1]) * opacity;
__m128i low_k = _mm_set1_epi16(k);
__m128i high_k1 = _mm_set1_epi16(k1);
__m128i k_v = _mm_unpackhi_epi64(low_k, high_k1);
high_k1 = _mm_mullo_epi16(k_v, rgb_v);
low_k = _mm_set1_epi16(255);
k_v = _mm_sub_epi16(low_k, k_v);
low_k = _mm_loadl_epi64((__m128i *)(now_dst));
low_k = _mm_unpacklo_epi8(low_k, zeros);
low_k = _mm_mullo_epi16(k_v, low_k);
low_k = _mm_add_epi16(high_k1, low_k);
low_k = _mm_fast_div_255_epu16(low_k);
low_k = _mm_packus_epi16(low_k, zeros);
_mm_storeu_si64(now_dst, low_k);
x += 2;
now_dst += 8;
}
if (x < img_w_tmp) {
__m128i rgb_v = _mm_set1_epi32(rgba);
rgb_v = _mm_unpacklo_epi8(rgb_v, zeros);
uint16_t k = ((unsigned int)src[x]) * opacity;
__m128i k_v = _mm_set1_epi16(k);
rgb_v = _mm_mullo_epi16(k_v, rgb_v);
__m128i sub_max = _mm_set1_epi16(255);
sub_max = _mm_sub_epi16(sub_max, k_v);
k_v = _mm_loadu_si32((__m128i *)(now_dst));
k_v = _mm_unpacklo_epi8(k_v, zeros);
k_v = _mm_mullo_epi16(sub_max, k_v);
k_v = _mm_add_epi16(rgb_v, k_v);
k_v = _mm_fast_div_255_epu16(k_v);
k_v = _mm_packus_epi16(k_v, zeros);
_mm_storeu_si32(now_dst, k_v);
}
src += img->stride;
dst += frame->stride;
}
}
void blend_u16_simd6(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd_method6(frame, img);
++cnt;
img = img->next;
}
}
void blend_single_u16_simd_method5(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
uint32_t rgba = _byteswap_ulong(img->color) | 0xFF;
unsigned char *src;
unsigned char *dst, *now_dst;
const int img_w_tmp = img->w;
__m128i zeros = _mm_setzero_si128();
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0, now_dst = dst; x <= img_w_tmp - 2;) {
__m128i rgb_v = _mm_set1_epi32(rgba);
rgb_v = _mm_unpacklo_epi8(rgb_v, zeros);
rgb_v = _mm_unpackhi_epi64(rgb_v, rgb_v);
uint16_t k = div_255_fast(((unsigned int)src[x]) * opacity);
uint16_t k1 = div_255_fast(((unsigned int)src[x + 1]) * opacity);
__m128i low_k = _mm_set1_epi16(k);
__m128i high_k1 = _mm_set1_epi16(k1);
__m128i k_v = _mm_unpackhi_epi64(low_k, high_k1);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
__m128i sub_max = _mm_set1_epi16(255);
__m128i k_v2 = _mm_sub_epi16(sub_max, k_v);
__m128i dst_v = _mm_loadl_epi64((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
res2 = _mm_packus_epi16(res2, zeros);
_mm_storeu_si64(now_dst, res2);
x += 2;
now_dst += 8;
}
if (x < img_w_tmp) {
__m128i rgb_v = _mm_set1_epi32(rgba);
rgb_v = _mm_unpacklo_epi8(rgb_v, zeros);
rgb_v = _mm_unpackhi_epi64(rgb_v, rgb_v);
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
__m128i low_k = _mm_set1_epi16(k);
__m128i k_v = _mm_unpackhi_epi64(low_k, low_k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
__m128i sub_max = _mm_set1_epi16(255);
__m128i k_v2 = _mm_sub_epi16(sub_max, k_v);
__m128i dst_v = _mm_loadu_si32((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
res2 = _mm_packus_epi16(res2, zeros);
_mm_storeu_si32(now_dst, res2);
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_u16_simd5(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd_method5(frame, img);
++cnt;
img = img->next;
}
}
inline void blend_single_u16_simd_method4(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned short r = TO_R(img->color);
unsigned short g = TO_G(img->color);
unsigned short b = TO_B(img->color);
unsigned char *src;
unsigned char *dst, *now_dst;
__m128i zeros = _mm_setzero_si128();
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0, now_dst = dst; x < img->w;) {
__m128i rgb_v = _mm_set_epi16(255, b, g, r, 255, b, g, r);
if (1) [[likely]] {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
uint16_t k1 = ((unsigned int)src[x + 1]) * opacity / 255;
__m128i low_k = _mm_set1_epi16(k);
__m128i high_k1 = _mm_set1_epi16(k1);
__m128i k_v = _mm_unpackhi_epi64(low_k, high_k1);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
__m128i sub_max = _mm_set1_epi16(255);
__m128i k_v2 = _mm_sub_epi16(sub_max, k_v);
__m128i dst_v = _mm_loadl_epi64((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
res2 = _mm_packus_epi16(res2, zeros);
_mm_storeu_si64(now_dst, res2);
x += 2;
now_dst += 8;
} else {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
__m128i k_v = _mm_set1_epi16(k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
__m128i k_v2 = _mm_set1_epi16(k);
__m128i dst_v = _mm_set_epi16(0, 0, 0, 0, dst[x * 4 + 3], dst[x * 4 + 2],
dst[x * 4 + 1], dst[x * 4]);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
__m128i packed;
_mm_store_si128(&packed, res2);
dst[x * 4] = packed.m128i_u8[0];
dst[x * 4 + 1] = packed.m128i_u8[2];
dst[x * 4 + 2] = packed.m128i_u8[4];
dst[x * 4 + 3] = packed.m128i_u8[6];
x++;
now_dst += 4;
}
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_u16_simd4(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd_method4(frame, img);
++cnt;
img = img->next;
}
}
inline void blend_single_u16_simd_method3(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned short r = TO_R(img->color);
unsigned short g = TO_G(img->color);
unsigned short b = TO_B(img->color);
unsigned char *src;
unsigned char *dst, *now_dst;
__m128i zeros = _mm_setzero_si128();
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0, now_dst = dst; x < img->w;) {
__m128i rgb_v = _mm_set_epi16(255, b, g, r, 255, b, g, r);
if (1) [[likely]] {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
uint16_t k1 = ((unsigned int)src[x + 1]) * opacity / 255;
__m128i low_k = _mm_set1_epi16(k);
__m128i high_k1 = _mm_set1_epi16(k1);
__m128i k_v = _mm_unpackhi_epi64(low_k, high_k1);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
k1 = 255 - k1;
low_k = _mm_set1_epi16(k);
high_k1 = _mm_set1_epi16(k1);
__m128i k_v2 = _mm_unpackhi_epi64(low_k, high_k1);
__m128i dst_v = _mm_loadl_epi64((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
res2 = _mm_packus_epi16(res2, zeros);
_mm_storeu_si64(now_dst, res2);
x += 2;
now_dst += 8;
} else {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
__m128i k_v = _mm_set1_epi16(k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
__m128i k_v2 = _mm_set1_epi16(k);
__m128i dst_v = _mm_set_epi16(0, 0, 0, 0, dst[x * 4 + 3], dst[x * 4 + 2],
dst[x * 4 + 1], dst[x * 4]);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
__m128i packed;
_mm_store_si128(&packed, res2);
dst[x * 4] = packed.m128i_u8[0];
dst[x * 4 + 1] = packed.m128i_u8[2];
dst[x * 4 + 2] = packed.m128i_u8[4];
dst[x * 4 + 3] = packed.m128i_u8[6];
x++;
now_dst += 4;
}
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_u16_simd3(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd_method3(frame, img);
++cnt;
img = img->next;
}
}
inline void blend_single_u16_simd_method2(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned short r = TO_R(img->color);
unsigned short g = TO_G(img->color);
unsigned short b = TO_B(img->color);
unsigned char *src;
unsigned char *dst, *now_dst;
__m128i zeros = _mm_setzero_si128();
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0, now_dst = dst; x < img->w;) {
__m128i rgb_v = _mm_set_epi16(255, b, g, r, 255, b, g, r);
if (1) [[likely]] {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
uint16_t k1 = ((unsigned int)src[x + 1]) * opacity / 255;
__m128i k_v = _mm_set_epi16(k1, k1, k1, k1, k, k, k, k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
k1 = 255 - k1;
__m128i k_v2 = _mm_set_epi16(k1, k1, k1, k1, k, k, k, k);
__m128i dst_v = _mm_loadl_epi64((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
res2 = _mm_packus_epi16(res2, zeros);
_mm_storeu_si64(now_dst, res2);
x += 2;
now_dst += 8;
} else {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
__m128i k_v = _mm_set1_epi16(k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
__m128i k_v2 = _mm_set1_epi16(k);
__m128i dst_v = _mm_set_epi16(0, 0, 0, 0, dst[x * 4 + 3], dst[x * 4 + 2],
dst[x * 4 + 1], dst[x * 4]);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
__m128i packed;
_mm_store_si128(&packed, res2);
dst[x * 4] = packed.m128i_u8[0];
dst[x * 4 + 1] = packed.m128i_u8[2];
dst[x * 4 + 2] = packed.m128i_u8[4];
dst[x * 4 + 3] = packed.m128i_u8[6];
x++;
now_dst += 4;
}
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_u16_simd2(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd_method2(frame, img);
++cnt;
img = img->next;
}
// printf("%d images blended\n", cnt);
}
inline void blend_single_u16_simd(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned short r = TO_R(img->color);
unsigned short g = TO_G(img->color);
unsigned short b = TO_B(img->color);
unsigned char *src;
unsigned char *dst;
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0; x < img->w;) {
__m128i rgb_v = _mm_set_epi16(255, b, g, r, 255, b, g, r);
if (img->w - x > 1) [[likely]] {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
uint16_t k1 = ((unsigned int)src[x + 1]) * opacity / 255;
__m128i k_v = _mm_set_epi16(k1, k1, k1, k1, k, k, k, k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
k1 = 255 - k1;
__m128i k_v2 = _mm_set_epi16(k1, k1, k1, k1, k, k, k, k);
__m128i dst_v = _mm_set_epi16(
dst[x * 4 + 7], dst[x * 4 + 6], dst[x * 4 + 5], dst[x * 4 + 4],
dst[x * 4 + 3], dst[x * 4 + 2], dst[x * 4 + 1], dst[x * 4]);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
__m128i packed;
_mm_store_si128(&packed, res2);
dst[x * 4] = packed.m128i_u8[0];
dst[x * 4 + 1] = packed.m128i_u8[2];
dst[x * 4 + 2] = packed.m128i_u8[4];
dst[x * 4 + 3] = packed.m128i_u8[6];
dst[x * 4 + 4] = packed.m128i_u8[8];
dst[x * 4 + 5] = packed.m128i_u8[10];
dst[x * 4 + 6] = packed.m128i_u8[12];
dst[x * 4 + 7] = packed.m128i_u8[14];
x += 2;
} else {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
__m128i k_v = _mm_set1_epi16(k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
__m128i k_v2 = _mm_set1_epi16(k);
__m128i dst_v = _mm_set_epi16(0, 0, 0, 0, dst[x * 4 + 3], dst[x * 4 + 2],
dst[x * 4 + 1], dst[x * 4]);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
__m128i packed;
_mm_store_si128(&packed, res2);
dst[x * 4] = packed.m128i_u8[0];
dst[x * 4 + 1] = packed.m128i_u8[2];
dst[x * 4 + 2] = packed.m128i_u8[4];
dst[x * 4 + 3] = packed.m128i_u8[6];
x++;
}
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_u16_simd(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd(frame, img);
++cnt;
img = img->next;
}
// printf("%d images blended\n", cnt);
}
#endif
inline void blend_single_normal_no_div(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned char r = TO_R(img->color);
unsigned char g = TO_G(img->color);
unsigned char b = TO_B(img->color);
unsigned char *src;
unsigned char *dst;
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0; x < img->w; ++x) {
uint32_t k = ((uint32_t)src[x]) * opacity;
// possible endianness problems...
// would anyone actually use big endian machine??
dst[x * 4] = (k * r + (255 * 255 - k) * dst[x * 4]) >> 16;
dst[x * 4 + 1] = (k * g + (255 * 255 - k) * dst[x * 4 + 1]) >> 16;
dst[x * 4 + 2] = (k * b + (255 * 255 - k) * dst[x * 4 + 2]) >> 16;
dst[x * 4 + 3] = (k * 255 + (255 * 255 - k) * dst[x * 4 + 3]) >> 16;
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_normal_no_div(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_normal_no_div(frame, img);
++cnt;
img = img->next;
}
// printf("%d images blended\n", cnt);
}
inline void blend_single_simd_no_div(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned char r = TO_R(img->color);
unsigned char g = TO_G(img->color);
unsigned char b = TO_B(img->color);
unsigned char *src;
unsigned char *dst;
src = img->bitmap;
// dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
dst = (frame->buffer) + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0; x < img->w; x++) {
uint32_t k = ((uint32_t)src[x]) * opacity;
uint32_t kk = 65025 - k;
uint8_t *dst_p = (uint8_t *)&dst[x << 2];
uint32_t dst_u32;
__m128 scale_dst = _mm_set1_ps((float)kk);
__m128i dst_32i = _mm_set_epi32(dst_p[3], dst_p[2], dst_p[1], dst_p[0]);
__m128 dst_ps = _mm_cvtepi32_ps(dst_32i);
__m128 scale_dst_res_ps = _mm_mul_ps(dst_ps, scale_dst);
__m128i scale_dst_res0_32i = _mm_cvtps_epi32(scale_dst_res_ps);
scale_dst = _mm_set1_ps((float)k);
dst_32i = _mm_set_epi32(255, b, g, r);
dst_ps = _mm_cvtepi32_ps(dst_32i);
scale_dst_res_ps = _mm_mul_ps(dst_ps, scale_dst);
__m128i scale_dst_res1_32i = _mm_cvtps_epi32(scale_dst_res_ps);
dst_32i = _mm_add_epi32(scale_dst_res0_32i, scale_dst_res1_32i);
__m128i res = _mm_srli_epi32(dst_32i, 16);
__m128i packed;
_mm_store_si128(&packed, res);
dst_p[0] = packed.m128i_u8[0];
dst_p[1] = packed.m128i_u8[4];
dst_p[2] = packed.m128i_u8[8];
dst_p[3] = packed.m128i_u8[12];
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_simd_no_div(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_simd_no_div(frame, img);
++cnt;
img = img->next;
}
}
inline void blend_single_intel_div(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned char r = TO_R(img->color);
unsigned char g = TO_G(img->color);
unsigned char b = TO_B(img->color);
unsigned char *src;
unsigned char *dst;
src = img->bitmap;
// dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
dst = (frame->buffer) + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0; x < img->w; x++) {
uint32_t k = ((uint32_t)src[x]) * opacity;
uint32_t kk = 65025 - k;
uint8_t *dst_p = (uint8_t *)&dst[x << 2];
uint32_t dst_u32;
__m128 scale_dst = _mm_set1_ps((float)kk);
__m128i dst_32i = _mm_set_epi32(dst_p[3], dst_p[2], dst_p[1], dst_p[0]);
__m128 dst_ps = _mm_cvtepi32_ps(dst_32i);
__m128 scale_dst_res_ps = _mm_mul_ps(dst_ps, scale_dst);
__m128i scale_dst_res0_32i = _mm_cvtps_epi32(scale_dst_res_ps);
scale_dst = _mm_set1_ps((float)k);
dst_32i = _mm_set_epi32(255, b, g, r);
dst_ps = _mm_cvtepi32_ps(dst_32i);
scale_dst_res_ps = _mm_mul_ps(dst_ps, scale_dst);
__m128i scale_dst_res1_32i = _mm_cvtps_epi32(scale_dst_res_ps);
dst_32i = _mm_add_epi32(scale_dst_res0_32i, scale_dst_res1_32i);
__m128i div_num = _mm_set1_epi32(65025);
__m128i res = _mm_div_epi32(dst_32i, div_num);
__m128i packed;
_mm_store_si128(&packed, res);
dst_p[0] = packed.m128i_u8[0];
dst_p[1] = packed.m128i_u8[4];
dst_p[2] = packed.m128i_u8[8];
dst_p[3] = packed.m128i_u8[12];
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_simd_intel_div(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_intel_div(frame, img);
++cnt;
img = img->next;
}
}
inline void blend_single_fast_div(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned char r = TO_R(img->color);
unsigned char g = TO_G(img->color);
unsigned char b = TO_B(img->color);
unsigned char *src;
unsigned char *dst;
src = img->bitmap;
// dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
dst = (frame->buffer) + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0; x < img->w; x++) {
uint32_t k = ((uint32_t)src[x]) * opacity;
uint32_t kk = 65025 - k;
uint8_t *dst_p = (uint8_t *)&dst[x << 2];
uint32_t dst_u32;
__m128 scale_dst = _mm_set1_ps((float)kk);
__m128i dst_32i = _mm_set_epi32(dst_p[3], dst_p[2], dst_p[1], dst_p[0]);
__m128 dst_ps = _mm_cvtepi32_ps(dst_32i);
__m128 scale_dst_res_ps = _mm_mul_ps(dst_ps, scale_dst);
__m128i scale_dst_res0_32i = _mm_cvtps_epi32(scale_dst_res_ps);
scale_dst = _mm_set1_ps((float)k);
dst_32i = _mm_set_epi32(255, b, g, r);
dst_ps = _mm_cvtepi32_ps(dst_32i);
scale_dst_res_ps = _mm_mul_ps(dst_ps, scale_dst);
__m128i scale_dst_res1_32i = _mm_cvtps_epi32(scale_dst_res_ps);
dst_32i = _mm_add_epi32(scale_dst_res0_32i, scale_dst_res1_32i);
#if 1
__m128i mult = _mm_set_epi64x(0x0203040602030406, 0x0203040602030406);
__m128i s1 = _mm_set_epi64x(0x0000000000000000, 0x0000000000000001);
__m128i s2 = _mm_set_epi64x(0x0000000000000000, 0x000000000000000f);
__m128i t1 = _mm_mul_epu32(
dst_32i, mult); // 32x32->64 bit unsigned multiplication of a[0] and a[2]
__m128i t2 = _mm_srli_epi64(t1, 32); // high dword of result 0 and 2
__m128i t3 = _mm_srli_epi64(
dst_32i, 32); // get a[1] and a[3] into position for multiplication
__m128i t4 = _mm_mul_epu32(
t3, mult); // 32x32->64 bit unsigned multiplication of a[1] and a[3]
#if 1 // SSE4.1 supported
__m128i t7 = _mm_blend_epi16(t2, t4, 0xCC); // blend two results
#else
__m128i t5 = _mm_set_epi32(-1, 0, -1, 0); // mask of dword 1 and 3
__m128i t6 = _mm_and_si128(t4, t5); // high dword of result 1 and 3
__m128i t7 = _mm_or_si128(t2, t6); // combine all four results into one vector
#endif
__m128i t8 = _mm_sub_epi32(dst_32i, t7); // subtract
__m128i t9 = _mm_srl_epi32(t8, s1); // shift right logical
__m128i t10 = _mm_add_epi32(t7, t9); // add
__m128i res = _mm_srl_epi32(t10, s2); // shift right logical
#endif
__m128i packed;
_mm_store_si128(&packed, res);
dst_p[0] = packed.m128i_u8[0];
dst_p[1] = packed.m128i_u8[4];
dst_p[2] = packed.m128i_u8[8];
dst_p[3] = packed.m128i_u8[12];
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_simd_fast_div(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_fast_div(frame, img);
++cnt;
img = img->next;
}
}
inline image_t *gen_image(int width, int height) {
image_t *img = (image_t *)malloc(sizeof(image_t));
img->width = width;
img->height = height;
img->stride = width * 4;
img->buffer = (unsigned char *)calloc(1, height * width * 4);
memset(img->buffer, 63, img->stride * img->height);
// for (int i = 0; i < height * width * 3; ++i)
// img->buffer[i] = (i/3/50) % 100;
return img;
}
inline void init(int frame_w, int frame_h) {
ass_library = ass_library_init();
if (!ass_library) {
printf("ass_library_init failed!\n");
exit(1);
}
ass_set_message_cb(ass_library, msg_callback, NULL);
ass_set_extract_fonts(ass_library, 1);
ass_renderer = ass_renderer_init(ass_library);
if (!ass_renderer) {
printf("ass_renderer_init failed!\n");
exit(1);
}
ass_set_frame_size(ass_renderer, frame_w, frame_h);
ass_set_fonts(ass_renderer, NULL, "sans-serif", ASS_FONTPROVIDER_AUTODETECT, NULL, 1);
}
int main() {
init(1920, 1080);
ASS_Track *track = ass_read_file(ass_library, (char *)"D:/a1.ass", NULL);
double cost_time;
int tm = 0;
image_t *frame = gen_image(1920, 1080);
// ass_set_cache_limits(ass_renderer, 0, 50);
tm = 0;
cost_time = 0;
#define TIME_LIMIT (250 * 15 * 20)
while (tm < TIME_LIMIT) {
ass_render_frame(ass_renderer, track, tm, NULL);
tm += ((double)(1000) / (double)(60));
}
std::cout << "start!" << std::endl;
std::cout << "-1-7] simd uint16 method7 div: ";
tm = 0;
cost_time = 0;
while (tm < TIME_LIMIT) {
ASS_Image *img = ass_render_frame(ass_renderer, track, tm, NULL);
// clear buffer
memset(frame->buffer, 0, 1920 * 1080 * 4);
auto job_start_time = std::chrono::high_resolution_clock::now();
blend_u16_simd7(frame, img);
auto job_end_time = std::chrono::high_resolution_clock::now();
cost_time +=
std::chrono::duration<double, std::milli>(job_end_time - job_start_time)
.count();
tm += ((double)(1000) / (double)(60));
}
std::cout << cost_time << " ms" << std::endl;
std::cout << "-1-6] simd uint16 method6 div: ";
tm = 0;
cost_time = 0;
while (tm < TIME_LIMIT) {
ASS_Image *img = ass_render_frame(ass_renderer, track, tm, NULL);
// clear buffer
memset(frame->buffer, 0, 1920 * 1080 * 4);
auto job_start_time = std::chrono::high_resolution_clock::now();
blend_u16_simd6(frame, img);
auto job_end_time = std::chrono::high_resolution_clock::now();
cost_time +=
std::chrono::duration<double, std::milli>(job_end_time - job_start_time)
.count();
tm += ((double)(1000) / (double)(60));
}
std::cout << cost_time << " ms" << std::endl;
std::cout << "-1-5] simd uint16 method5 div: ";
tm = 0;
cost_time = 0;
while (tm < TIME_LIMIT) {
ASS_Image *img = ass_render_frame(ass_renderer, track, tm, NULL);
// clear buffer
memset(frame->buffer, 0, 1920 * 1080 * 4);
auto job_start_time = std::chrono::high_resolution_clock::now();
blend_u16_simd5(frame, img);
auto job_end_time = std::chrono::high_resolution_clock::now();
cost_time +=
std::chrono::duration<double, std::milli>(job_end_time - job_start_time)
.count();
tm += ((double)(1000) / (double)(60));
}
std::cout << cost_time << " ms" << std::endl;
std::cout << "-1-4] simd uint16 method4 div: ";
tm = 0;
cost_time = 0;
while (tm < TIME_LIMIT) {
ASS_Image *img = ass_render_frame(ass_renderer, track, tm, NULL);
// clear buffer
memset(frame->buffer, 0, 1920 * 1080 * 4);
auto job_start_time = std::chrono::high_resolution_clock::now();
blend_u16_simd4(frame, img);
auto job_end_time = std::chrono::high_resolution_clock::now();
cost_time +=
std::chrono::duration<double, std::milli>(job_end_time - job_start_time)
.count();
tm += ((double)(1000) / (double)(60));
}
std::cout << cost_time << " ms" << std::endl;
std::cout << "-1-3] simd uint16 method3 div: ";
tm = 0;
cost_time = 0;
while (tm < TIME_LIMIT) {
ASS_Image *img = ass_render_frame(ass_renderer, track, tm, NULL);
// clear buffer
memset(frame->buffer, 0, 1920 * 1080 * 4);
auto job_start_time = std::chrono::high_resolution_clock::now();
blend_u16_simd3(frame, img);
auto job_end_time = std::chrono::high_resolution_clock::now();
cost_time +=
std::chrono::duration<double, std::milli>(job_end_time - job_start_time)
.count();
tm += ((double)(1000) / (double)(60));
}
std::cout << cost_time << " ms" << std::endl;
std::cout << "-1-2] simd uint16 method2 div: ";
tm = 0;
cost_time = 0;
while (tm < TIME_LIMIT) {
ASS_Image *img = ass_render_frame(ass_renderer, track, tm, NULL);
// clear buffer
memset(frame->buffer, 0, 1920 * 1080 * 4);
auto job_start_time = std::chrono::high_resolution_clock::now();
blend_u16_simd2(frame, img);
auto job_end_time = std::chrono::high_resolution_clock::now();
cost_time +=
std::chrono::duration<double, std::milli>(job_end_time - job_start_time)
.count();
tm += ((double)(1000) / (double)(60));
}
std::cout << cost_time << " ms" << std::endl;
std::cout << "-1] simd uint16 div: ";
tm = 0;
cost_time = 0;
while (tm < TIME_LIMIT) {
ASS_Image *img = ass_render_frame(ass_renderer, track, tm, NULL);
// clear buffer
memset(frame->buffer, 0, 1920 * 1080 * 4);
auto job_start_time = std::chrono::high_resolution_clock::now();
blend_u16_simd(frame, img);
auto job_end_time = std::chrono::high_resolution_clock::now();
cost_time +=
std::chrono::duration<double, std::milli>(job_end_time - job_start_time)
.count();
tm += ((double)(1000) / (double)(60));
}
std::cout << cost_time << " ms" << std::endl;
std::cout << "0] normal no div: ";
tm = 0;
cost_time = 0;
while (tm < TIME_LIMIT) {
ASS_Image *img = ass_render_frame(ass_renderer, track, tm, NULL);
// clear buffer
memset(frame->buffer, 0, 1920 * 1080 * 4);
auto job_start_time = std::chrono::high_resolution_clock::now();
blend_normal_no_div(frame, img);
auto job_end_time = std::chrono::high_resolution_clock::now();
cost_time +=
std::chrono::duration<double, std::milli>(job_end_time - job_start_time)
.count();
tm += ((double)(1000) / (double)(60));
}
std::cout << cost_time << " ms" << std::endl;
std::cout << "1] normal method: ";
tm = 0;
cost_time = 0;
while (tm < TIME_LIMIT) {
ASS_Image *img = ass_render_frame(ass_renderer, track, tm, NULL);
// clear buffer
memset(frame->buffer, 0, 1920 * 1080 * 4);
auto job_start_time = std::chrono::high_resolution_clock::now();
blend(frame, img);
auto job_end_time = std::chrono::high_resolution_clock::now();
cost_time +=
std::chrono::duration<double, std::milli>(job_end_time - job_start_time)
.count();
tm += ((double)(1000) / (double)(60));
}
std::cout << cost_time << " ms" << std::endl;
std::cout << "3] fast div: ";
tm = 0;
cost_time = 0;
while (tm < TIME_LIMIT) {
ASS_Image *img = ass_render_frame(ass_renderer, track, tm, NULL);
// clear buffer
memset(frame->buffer, 0, 1920 * 1080 * 4);
auto job_start_time = std::chrono::high_resolution_clock::now();
blend_simd_fast_div(frame, img);
auto job_end_time = std::chrono::high_resolution_clock::now();
cost_time +=
std::chrono::duration<double, std::milli>(job_end_time - job_start_time)
.count();
tm += ((double)(1000) / (double)(60));
}
std::cout << cost_time << " ms" << std::endl;
std::cout << "4] no div: ";
tm = 0;
cost_time = 0;
while (tm < TIME_LIMIT) {
ASS_Image *img = ass_render_frame(ass_renderer, track, tm, NULL);
// clear buffer
memset(frame->buffer, 0, 1920 * 1080 * 4);
auto job_start_time = std::chrono::high_resolution_clock::now();
blend_simd_no_div(frame, img);
auto job_end_time = std::chrono::high_resolution_clock::now();
cost_time +=
std::chrono::duration<double, std::milli>(job_end_time - job_start_time)
.count();
tm += ((double)(1000) / (double)(60));
}
std::cout << cost_time << " ms" << std::endl;
std::cout << "Done!\n";
return 0;
}改进版本: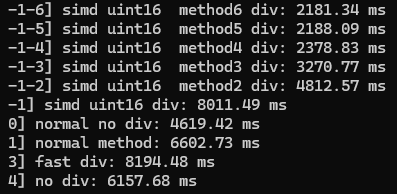
#include <cstring>
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <string>
#include <stdint.h>
#include <immintrin.h>
#include <smmintrin.h>
#include "thirdparty/libass/include/ass.h"
#include <chrono>
#if defined(_WIN32) || defined(_WIN64)
#define POPEN _popen
#define PCLOSE _pclose
const char *kOpenOption = "wb";
#else
#define POPEN popen
#define PCLOSE pclose
const char *kOpenOption = "w";
#endif
extern "C" {
int ass_process_events_line(ASS_Track *track, char *str);
}
ASS_Library *ass_library;
ASS_Renderer *ass_renderer;
typedef struct image_s {
int width, height, stride;
unsigned char *buffer; // RGB24
} image_t;
void msg_callback(int level, const char *fmt, va_list va, void *data) {
if (level > 6)
return;
printf("libass: ");
vprintf(fmt, va);
printf("\n");
}
#define TO_R(c) ((c) >> 24)
#define TO_G(c) (((c) >> 16) & 0xFF)
#define TO_B(c) (((c) >> 8) & 0xFF)
#define TO_A(c) ((c)&0xFF)
inline void blend_single(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned char r = TO_R(img->color);
unsigned char g = TO_G(img->color);
unsigned char b = TO_B(img->color);
unsigned char *src;
unsigned char *dst;
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0; x < img->w; ++x) {
uint32_t k = ((uint32_t)src[x]) * opacity;
// possible endianness problems...
// would anyone actually use big endian machine??
dst[x * 4] = (k * r + (255 * 255 - k) * dst[x * 4]) / (255 * 255);
dst[x * 4 + 1] = (k * g + (255 * 255 - k) * dst[x * 4 + 1]) / (255 * 255);
dst[x * 4 + 2] = (k * b + (255 * 255 - k) * dst[x * 4 + 2]) / (255 * 255);
dst[x * 4 + 3] = (k * 255 + (255 * 255 - k) * dst[x * 4 + 3]) / (255 * 255);
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single(frame, img);
++cnt;
img = img->next;
}
// printf("%d images blended\n", cnt);
}
inline int div_255_fast(int x) { return (((x) + (((x) + 257) >> 8)) >> 8); }
//#define div_255_fast(A) ((A) / 255)
inline void blend_single_normal_fast_div_single(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned char r = TO_R(img->color);
unsigned char g = TO_G(img->color);
unsigned char b = TO_B(img->color);
unsigned char *src;
unsigned char *dst;
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0; x < img->w; ++x) {
unsigned k = div_255_fast(((unsigned)src[x]) * opacity);
// possible endianness problems
dst[x * 4] = div_255_fast(k * r + (255 - k) * dst[x * 4]);
dst[x * 4 + 1] = div_255_fast(k * g + (255 - k) * dst[x * 4 + 1]);
dst[x * 4 + 2] = div_255_fast(k * b + (255 - k) * dst[x * 4 + 2]);
dst[x * 4 + 3] = div_255_fast(k * 255 + (255 - k) * dst[x * 4 + 3]);
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_normal_fast_div(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_normal_fast_div_single(frame, img);
++cnt;
img = img->next;
}
// printf("%d images blended\n", cnt);
}
#if 1
static inline __m128i _mm_fast_div_255_epu16(__m128i x) {
return _mm_srli_epi16(
_mm_adds_epu16(x, _mm_srli_epi16(_mm_adds_epu16(x, _mm_set1_epi16(0x0101)), 8)),
8);
}
inline void blend_single_u16_simd_method6(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
uint32_t rgba = _byteswap_ulong(img->color) | 0xFF;
unsigned char *src;
unsigned char *dst, *now_dst;
const int img_w_tmp = img->w;
__m128i zeros = _mm_setzero_si128();
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0, now_dst = dst; x <= img_w_tmp - 2;) {
__m128i rgb_v = _mm_set1_epi32(rgba);
rgb_v = _mm_unpacklo_epi8(rgb_v, zeros);
rgb_v = _mm_unpackhi_epi64(rgb_v, rgb_v);
uint16_t k = div_255_fast(((unsigned int)src[x]) * opacity);
uint16_t k1 = div_255_fast(((unsigned int)src[x + 1]) * opacity);
__m128i low_k = _mm_set1_epi16(k);
__m128i high_k1 = _mm_set1_epi16(k1);
__m128i k_v = _mm_unpackhi_epi64(low_k, high_k1);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
__m128i sub_max = _mm_set1_epi16(255);
__m128i k_v2 = _mm_sub_epi16(sub_max, k_v);
__m128i dst_v = _mm_loadl_epi64((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
res1 = _mm_fast_div_255_epu16(res1);
res1 = _mm_packus_epi16(res1, zeros);
_mm_storeu_si64(now_dst, res1);
x += 2;
now_dst += 8;
}
if (x < img_w_tmp) {
__m128i rgb_v = _mm_set1_epi32(rgba);
rgb_v = _mm_unpacklo_epi8(rgb_v, zeros);
rgb_v = _mm_unpackhi_epi64(rgb_v, rgb_v);
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
__m128i low_k = _mm_set1_epi16(k);
__m128i k_v = _mm_unpackhi_epi64(low_k, low_k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
__m128i sub_max = _mm_set1_epi16(255);
__m128i k_v2 = _mm_sub_epi16(sub_max, k_v);
__m128i dst_v = _mm_loadu_si32((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
res2 = _mm_packus_epi16(res2, zeros);
_mm_storeu_si32(now_dst, res2);
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_u16_simd6(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd_method6(frame, img);
++cnt;
img = img->next;
}
}
inline void blend_single_u16_simd_method5(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
uint32_t rgba = _byteswap_ulong(img->color) | 0xFF;
unsigned char *src;
unsigned char *dst, *now_dst;
const int img_w_tmp = img->w;
__m128i zeros = _mm_setzero_si128();
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0, now_dst = dst; x <= img_w_tmp - 2;) {
__m128i rgb_v = _mm_set1_epi32(rgba);
rgb_v = _mm_unpacklo_epi8(rgb_v, zeros);
rgb_v = _mm_unpackhi_epi64(rgb_v, rgb_v);
uint16_t k = div_255_fast(((unsigned int)src[x]) * opacity);
uint16_t k1 = div_255_fast(((unsigned int)src[x + 1]) * opacity);
__m128i low_k = _mm_set1_epi16(k);
__m128i high_k1 = _mm_set1_epi16(k1);
__m128i k_v = _mm_unpackhi_epi64(low_k, high_k1);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
__m128i sub_max = _mm_set1_epi16(255);
__m128i k_v2 = _mm_sub_epi16(sub_max, k_v);
__m128i dst_v = _mm_loadl_epi64((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
res2 = _mm_packus_epi16(res2, zeros);
_mm_storeu_si64(now_dst, res2);
x += 2;
now_dst += 8;
}
if (x < img_w_tmp) {
__m128i rgb_v = _mm_set1_epi32(rgba);
rgb_v = _mm_unpacklo_epi8(rgb_v, zeros);
rgb_v = _mm_unpackhi_epi64(rgb_v, rgb_v);
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
__m128i low_k = _mm_set1_epi16(k);
__m128i k_v = _mm_unpackhi_epi64(low_k, low_k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
__m128i sub_max = _mm_set1_epi16(255);
__m128i k_v2 = _mm_sub_epi16(sub_max, k_v);
__m128i dst_v = _mm_loadu_si32((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
res2 = _mm_packus_epi16(res2, zeros);
_mm_storeu_si32(now_dst, res2);
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_u16_simd5(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd_method5(frame, img);
++cnt;
img = img->next;
}
}
inline void blend_single_u16_simd_method4(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned short r = TO_R(img->color);
unsigned short g = TO_G(img->color);
unsigned short b = TO_B(img->color);
unsigned char *src;
unsigned char *dst, *now_dst;
__m128i zeros = _mm_setzero_si128();
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0, now_dst = dst; x < img->w;) {
__m128i rgb_v = _mm_set_epi16(255, b, g, r, 255, b, g, r);
if (1)
[[likely]] {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
uint16_t k1 = ((unsigned int)src[x + 1]) * opacity / 255;
__m128i low_k = _mm_set1_epi16(k);
__m128i high_k1 = _mm_set1_epi16(k1);
__m128i k_v = _mm_unpackhi_epi64(low_k, high_k1);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
__m128i sub_max = _mm_set1_epi16(255);
__m128i k_v2 = _mm_sub_epi16(sub_max, k_v);
__m128i dst_v = _mm_loadl_epi64((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
res2 = _mm_packus_epi16(res2, zeros);
_mm_storeu_si64(now_dst, res2);
x += 2;
now_dst += 8;
}
else {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
__m128i k_v = _mm_set1_epi16(k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
__m128i k_v2 = _mm_set1_epi16(k);
__m128i dst_v = _mm_set_epi16(0, 0, 0, 0, dst[x * 4 + 3], dst[x * 4 + 2],
dst[x * 4 + 1], dst[x * 4]);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
__m128i packed;
_mm_store_si128(&packed, res2);
dst[x * 4] = packed.m128i_u8[0];
dst[x * 4 + 1] = packed.m128i_u8[2];
dst[x * 4 + 2] = packed.m128i_u8[4];
dst[x * 4 + 3] = packed.m128i_u8[6];
x++;
now_dst += 4;
}
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_u16_simd4(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd_method4(frame, img);
++cnt;
img = img->next;
}
}
inline void blend_single_u16_simd_method3(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned short r = TO_R(img->color);
unsigned short g = TO_G(img->color);
unsigned short b = TO_B(img->color);
unsigned char *src;
unsigned char *dst, *now_dst;
__m128i zeros = _mm_setzero_si128();
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0, now_dst = dst; x < img->w;) {
__m128i rgb_v = _mm_set_epi16(255, b, g, r, 255, b, g, r);
if (1)
[[likely]] {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
uint16_t k1 = ((unsigned int)src[x + 1]) * opacity / 255;
__m128i low_k = _mm_set1_epi16(k);
__m128i high_k1 = _mm_set1_epi16(k1);
__m128i k_v = _mm_unpackhi_epi64(low_k, high_k1);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
k1 = 255 - k1;
low_k = _mm_set1_epi16(k);
high_k1 = _mm_set1_epi16(k1);
__m128i k_v2 = _mm_unpackhi_epi64(low_k, high_k1);
__m128i dst_v = _mm_loadl_epi64((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
res2 = _mm_packus_epi16(res2, zeros);
_mm_storeu_si64(now_dst, res2);
x += 2;
now_dst += 8;
}
else {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
__m128i k_v = _mm_set1_epi16(k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
__m128i k_v2 = _mm_set1_epi16(k);
__m128i dst_v = _mm_set_epi16(0, 0, 0, 0, dst[x * 4 + 3], dst[x * 4 + 2],
dst[x * 4 + 1], dst[x * 4]);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
__m128i packed;
_mm_store_si128(&packed, res2);
dst[x * 4] = packed.m128i_u8[0];
dst[x * 4 + 1] = packed.m128i_u8[2];
dst[x * 4 + 2] = packed.m128i_u8[4];
dst[x * 4 + 3] = packed.m128i_u8[6];
x++;
now_dst += 4;
}
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_u16_simd3(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd_method3(frame, img);
++cnt;
img = img->next;
}
}
inline void blend_single_u16_simd_method2(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned short r = TO_R(img->color);
unsigned short g = TO_G(img->color);
unsigned short b = TO_B(img->color);
unsigned char *src;
unsigned char *dst, *now_dst;
__m128i zeros = _mm_setzero_si128();
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0, now_dst = dst; x < img->w;) {
__m128i rgb_v = _mm_set_epi16(255, b, g, r, 255, b, g, r);
if (1)
[[likely]] {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
uint16_t k1 = ((unsigned int)src[x + 1]) * opacity / 255;
__m128i k_v = _mm_set_epi16(k1, k1, k1, k1, k, k, k, k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
k1 = 255 - k1;
__m128i k_v2 = _mm_set_epi16(k1, k1, k1, k1, k, k, k, k);
__m128i dst_v = _mm_loadl_epi64((__m128i *)(now_dst));
dst_v = _mm_unpacklo_epi8(dst_v, zeros);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
res2 = _mm_packus_epi16(res2, zeros);
_mm_storeu_si64(now_dst, res2);
x += 2;
now_dst += 8;
}
else {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
__m128i k_v = _mm_set1_epi16(k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
__m128i k_v2 = _mm_set1_epi16(k);
__m128i dst_v = _mm_set_epi16(0, 0, 0, 0, dst[x * 4 + 3], dst[x * 4 + 2],
dst[x * 4 + 1], dst[x * 4]);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
__m128i packed;
_mm_store_si128(&packed, res2);
dst[x * 4] = packed.m128i_u8[0];
dst[x * 4 + 1] = packed.m128i_u8[2];
dst[x * 4 + 2] = packed.m128i_u8[4];
dst[x * 4 + 3] = packed.m128i_u8[6];
x++;
now_dst += 4;
}
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_u16_simd2(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd_method2(frame, img);
++cnt;
img = img->next;
}
// printf("%d images blended\n", cnt);
}
inline void blend_single_u16_simd(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned short r = TO_R(img->color);
unsigned short g = TO_G(img->color);
unsigned short b = TO_B(img->color);
unsigned char *src;
unsigned char *dst;
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0; x < img->w;) {
__m128i rgb_v = _mm_set_epi16(255, b, g, r, 255, b, g, r);
if (img->w - x > 1)
[[likely]] {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
uint16_t k1 = ((unsigned int)src[x + 1]) * opacity / 255;
__m128i k_v = _mm_set_epi16(k1, k1, k1, k1, k, k, k, k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
k1 = 255 - k1;
__m128i k_v2 = _mm_set_epi16(k1, k1, k1, k1, k, k, k, k);
__m128i dst_v = _mm_set_epi16(
dst[x * 4 + 7], dst[x * 4 + 6], dst[x * 4 + 5], dst[x * 4 + 4],
dst[x * 4 + 3], dst[x * 4 + 2], dst[x * 4 + 1], dst[x * 4]);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
__m128i packed;
_mm_store_si128(&packed, res2);
dst[x * 4] = packed.m128i_u8[0];
dst[x * 4 + 1] = packed.m128i_u8[2];
dst[x * 4 + 2] = packed.m128i_u8[4];
dst[x * 4 + 3] = packed.m128i_u8[6];
dst[x * 4 + 4] = packed.m128i_u8[8];
dst[x * 4 + 5] = packed.m128i_u8[10];
dst[x * 4 + 6] = packed.m128i_u8[12];
dst[x * 4 + 7] = packed.m128i_u8[14];
x += 2;
}
else {
uint16_t k = ((unsigned int)src[x]) * opacity / 255;
__m128i k_v = _mm_set1_epi16(k);
__m128i mul_1 = _mm_mullo_epi16(k_v, rgb_v);
k = 255 - k;
__m128i k_v2 = _mm_set1_epi16(k);
__m128i dst_v = _mm_set_epi16(0, 0, 0, 0, dst[x * 4 + 3], dst[x * 4 + 2],
dst[x * 4 + 1], dst[x * 4]);
__m128i mul_2 = _mm_mullo_epi16(k_v2, dst_v);
__m128i res1 = _mm_add_epi16(mul_1, mul_2);
__m128i res2 = _mm_fast_div_255_epu16(res1);
__m128i packed;
_mm_store_si128(&packed, res2);
dst[x * 4] = packed.m128i_u8[0];
dst[x * 4 + 1] = packed.m128i_u8[2];
dst[x * 4 + 2] = packed.m128i_u8[4];
dst[x * 4 + 3] = packed.m128i_u8[6];
x++;
}
}
src += img->stride;
dst += frame->stride;
}
}
inline void blend_u16_simd(image_t *frame, ASS_Image *img) {
int cnt = 0;
while (img) {
blend_single_u16_simd(frame, img);
++cnt;
img = img->next;
}
// printf("%d images blended\n", cnt);
}
#endif
inline void blend_single_normal_no_div(image_t *frame, ASS_Image *img) {
int x, y;
unsigned char opacity = 255 - TO_A(img->color);
unsigned char r = TO_R(img->color);
unsigned char g = TO_G(img->color);
unsigned char b = TO_B(img->color);
unsigned char *src;
unsigned char *dst;
src = img->bitmap;
dst = frame->buffer + img->dst_y * frame->stride + img->dst_x * 4;
for (y = 0; y < img->h; ++y) {
for (x = 0; x < img->w; ++x) {
uint32_t k = ((uint32_t)src[x]) * opacity;
// possible endianness problems...
// would anyone actually use big endian machine??