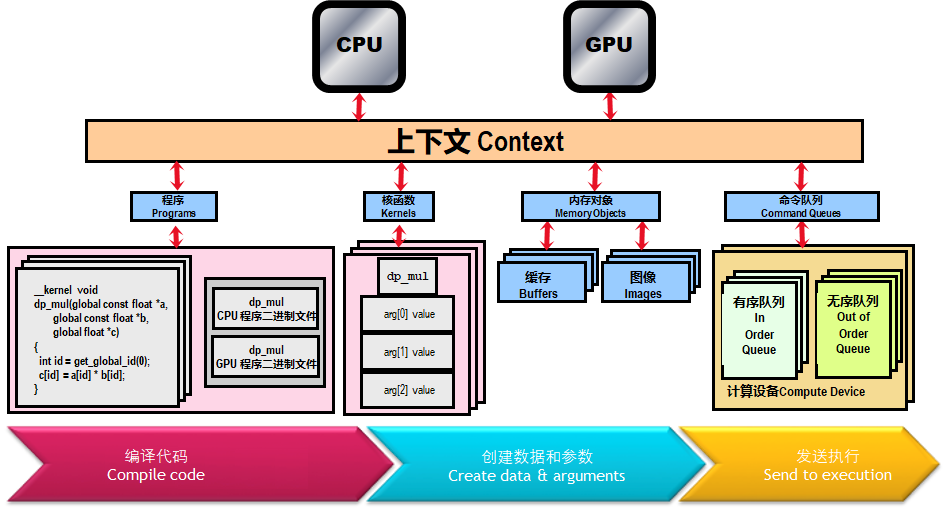
OpenCL入门
1. OpenCL平台样例
- CPU平台
- 看做一个 OpenCL 设备(device)
每个核心(core)一个计算单元(CU)
每个计算单元一个处理元素(PE),或者如果 PE 映射到单指令多数据流(SIMD lanes),则每个 CU 有 n 个 ,这里的 n 等同于单指令多数据流的带宽( SIMD width )
- 记住:
CPU本身也是自己的宿主(Host)
- GPU平台
- 每个 GPU 是一个单独的 OpenCL 设备(device)
- 通过 OpenCL 可以同时使用 CPU 和所有 GPU 设备
2. OpenCL平台模型
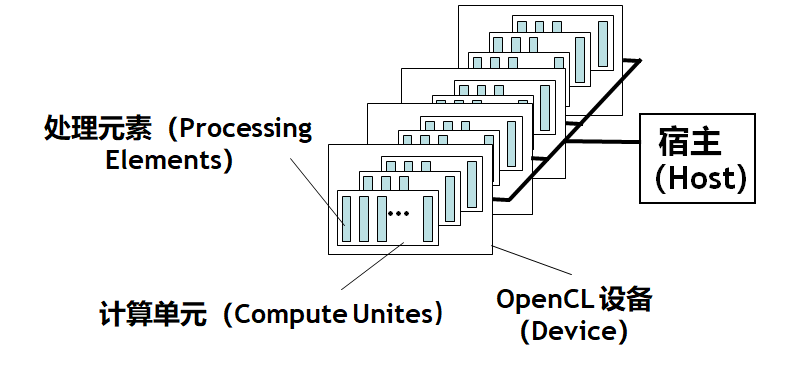
- 一个宿主(Host)以及一个或者多个 OpenCL 设备 (Device)每个 OpenCL 设备都由一个或者多个计算单元(Compute Units)组成,计算单元后文常缩写为 CU 每个计算单元都可以分成一个或者多个处理元素(Processing Elements),后文缩写为 PE
- 内存(Memory)分为宿主内存(host memory)和设备内存(device memory)
3. 初识并行运算
- 传统循环
void mul(const int n,
const float *a,
const float *b,
float *c)
{
int i;
for (i = 0; i < n; i++)
c[i] = a[i] * b[i];
}- 并行运算
__kernel void
mul(__global const float *a,
__global const float *b,
__global float *c)
{
int id = get_global_id(0);
c[id] = a[id] * b[id];
}
// 称为工作项目的
// 很多核函数的实例
// 都是并行执行的
工作项( work-items )的N维域( N-dimensional domain )
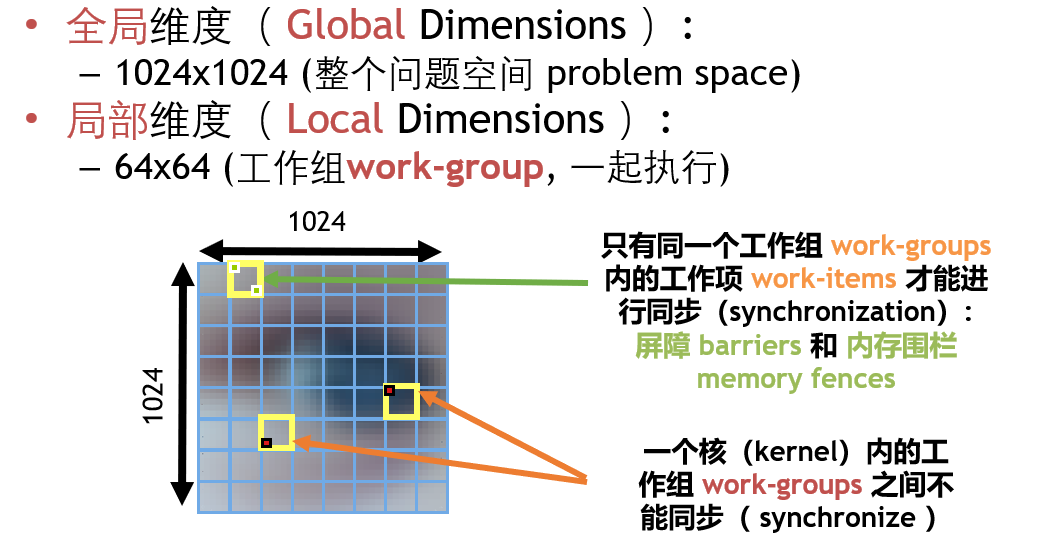
通过并行计算解决问题的前提
我们要计算的问题应该具有某一个确定的维度(dimensionality);
- 假设要针对一个立方体(cube)上面的所有点计算一个核函数(kernel)
- 运行这个核函数(kernel)的时候就要指定最高为三维(up to 3 dimensions)
- 还要指定每个维度上的问题规模 (specify the total problem size )– 这叫做全局规模(global size)。
- 然后将迭代空间(iteration space)中的每个点关联到一个工作项(work-item)。
OpenCL内存模型
- 私有内存 Private Memory
- 每个工作项 work-item
- 局部内存 Local Memory
- 工作组 work-group 内分享
- 全局内存/恒定内存Global Memory /Constant Memory
-对所有工作组都可见 宿主内存 Host memory
- 在 CPU 上
内存管理是 明确的、显式的( explicit ): 你要负责把数据在 宿主 host → 全局 global → 局部 local 之间来回移动
执行模型(核函数)的相关示例
OpenCL 执行模型( execution model )… 定义一个问题域(problem domain)然后对域中每个点运行一个核函数实例(instance of a kernel)。
下面是一个将所有的元素乘以2的示例:
__kernel void times_two(
__global float* input,
__global float* output)
{
int i = get_global_id(0);
output[i] = 2.0f * input[i];
}基本的运行架构